Autoscaling
Learn how Neon automatically scales compute resources on demand
Neon's Autoscaling feature, available to paying users, dynamically adjusts the amount of compute resources allocated to a Neon compute endpoint in response to the current load, eliminating the need for manual intervention.
Autoscaling benefits
Neon's Autoscaling feature offers the following benefits:
- On-demand scaling: Autoscaling helps with workloads that experience variations over time, such as applications with regional or time-based changes in demand.
- Cost-effectiveness: Autoscaling optimizes resource utilization, ensuring that organizations only pay for required resources, rather than over-provisioning to handle peak loads.
- Resource and cost control: Autoscaling operates within a user-defined range, ensuring that your compute resources and associated costs do not scale indefinitely.
- No manual intervention: After you enable autoscaling and set scaling limits, no manual intervention is required, allowing you to focus on your applications.
How to enable autoscaling
You can enable autoscaling when creating a Neon project or afterward using a simple compute configuration dialog. For instructions, see:
How autoscaling works
A Neon project can have one or more computes, each representing an individual Postgres instance. Storage is decoupled from these computes, meaning that the Postgres servers executing queries are physically separate from the data storage location. This separation offers numerous advantages, including enablement of Neon's autoscaling feature.
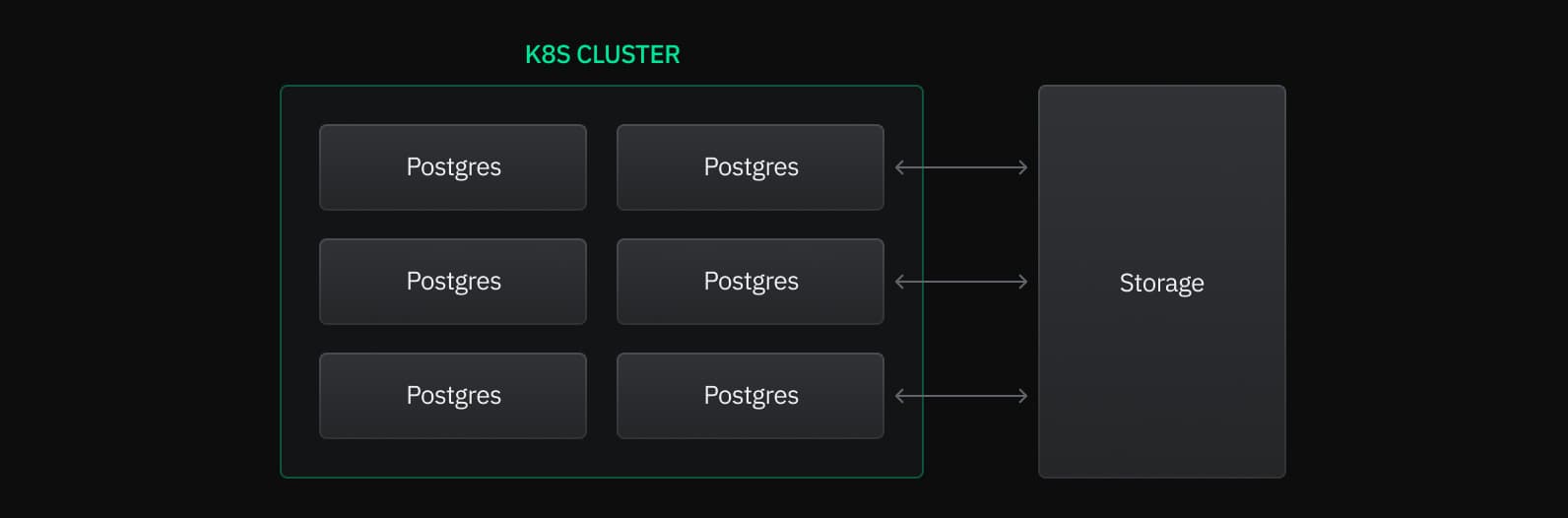
Looking more closely, you can see that each Postgres instance operates within its own virtual machine inside a Kubernetes cluster, with multiple VMs hosted on each node of the cluster. Autoscaling is implemented by allocating and deallocating vCPU and RAM to each VM.
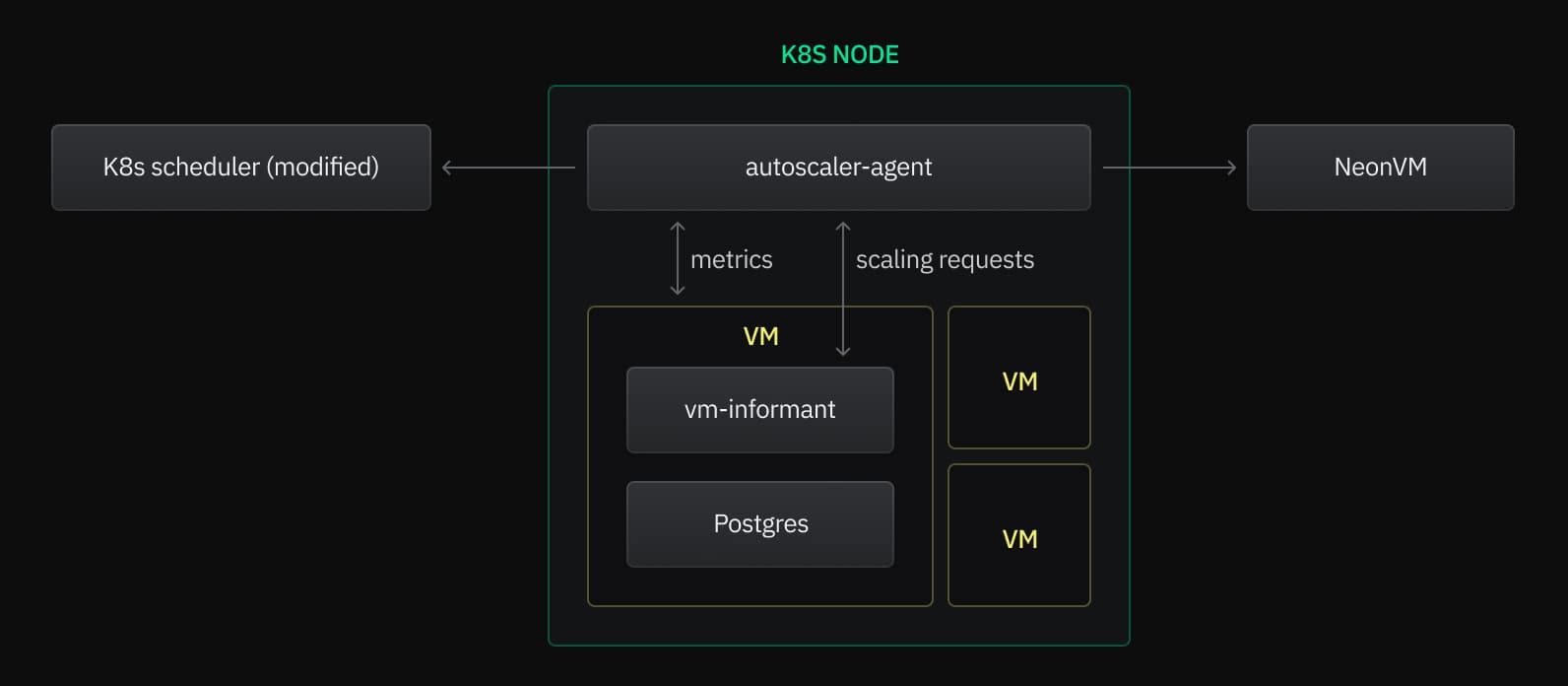
The autoscaler-agent
Each Kubernetes node hosts a single instance of the autoscaler-agent, which serves as the control mechanism for Neon's autoscaling system. The agent collects metrics from the VMs on its node, makes scaling decisions, and performs the necessary checks and requests to implement those decisions.
The Kubernetes scheduler
A Neon-modified Kubernetes scheduler coordinates with the autoscaler-agent and is the single source of truth for resource allocation. The autoscaler-agent obtains approval for all upscaling from the scheduler. The scheduler maintains a global view of all resource usage changes and approves requests for additional resources from the autoscaler-agent or standard scheduling. In this way, the scheduler assumes responsibility for preventing overcommitting of memory resources. In the rare event that a node exhausts its resources, new pods are not scheduled on the node, and the autoscaler-agent is denied permission to allocate more resources.
NeonVM
Kubernetes does not natively support the creation or management of VMs. To address this, Neon uses a tool called NeonVM. This tool is a custom resource definition and controller for VMs, handling tasks such as adding or removing CPUs and memory. Internally, NeonVM utilizes QEMU and KVM (where available) to achieve near-native performance.
When an autoscaler-agent needs to modify a VM's resource allocation, it simply updates the corresponding NeonVM object in Kubernetes, and the VM controller then manages the rest of the process.
Live migration
In cases where a Kubernetes node becomes saturated, NeonVM manages the process of live migrating a VM, transferring the VM from one machine to another with minimal interruptions (typically around 100ms). Live migration transmits the internal state of the original VM to a new one while the former continues to operate, swiftly transitioning to the new VM after most of the data is copied. From within the VM, the only indication that a migration occurred might be a temporary performance reduction. Importantly, the VM retains its IP address, ensuring that connections are preserved and queries remain uninterrupted.
The live migration process allows for the proactive reduction of node load by migrating VMs away before reaching capacity. Although it is still possible for the node to fill up in the interim, Neon's separation of storage and compute means that VMs typically use minimal disk space, resulting in fast migrations.
Memory scaling
Postgres memory consumption can escalate rapidly in specific scenarios. Fortunately, Neon's autoscaling system is able to detect memory usage increases without constantly requesting metrics from the VM. This is accomplished by running Postgres within a cgroups, which provides notifications when memory usage crosses a specified threshold. Using cgroups in this way requires running our vm-informant in the VM alongside Postgres to request more resources from the autoscaler-agent when Postgres consumes too much memory. The vm-informant also verifies that downscaling requests from an autoscaler-agent will leave sufficient memory leftover.
Local file cache
To expedite queries, the autoscaling system incorporates a Postgres extension that places a cache in front of the storage layer. Many queries benefit from this additional memory, particularly those requiring multiple database scans (such as creating an index). The local file cache capitalizes on the additional memory allocated to the VM by dedicating a portion to the cache to itself. The cache is backed by disk and kept at a size intended to fit in the kernel page cache. Due to the storage model, writebacks are not required, resulting in near-instant evictions. The vm-informant adjusts the local file cache size when scaling occurs through the autoscaler-agent, ensuring seamless operation.
Autoscaling source code
To further explore Neon's autoscaling implementation, visit Neon's autoscaling GitHub repository. While not primarily designed for external use, Neon welcomes exploration and contributions.
Last updated on