The pg_embedding extension (Support Discontinued)
warning
As of Sept 29, 2023, Neon is no longer committing to pg_embedding.
Support will remain in place for existing users of the extension, but we strongly encourage migrating to pgvector.
For migration instructions, see Migrate from pg_embedding to pgvector.
Migrate from pg_embedding to pgvector
The pg_embedding extension stores embeddings in real[] type columns, while pgvector uses vector type columns. To migrate from pg_embedding to pg_vector, you have two options:
- Use casting: Keep your embeddings data as it is, in
real[]type columns, and cast fromreal[]tovectorin your queries and index creation statements. - Use the vector type: Recreate your table using the
vectortype instead ofreal[]. This method requires copying data from one table to another.
Both migration methods are described below.
The migration instructions are based on the following setup, which has the pg_embedding extension installed, a table named documents defined with a real[] column named embedding, and an hnsw index defined on the embeddings column. You have to adapt the queries in the migration instructions according to your setup.
CREATE EXTENSION embedding;
CREATE TABLE documents(id BIGSERIAL PRIMARY KEY, embedding real[]);
INSERT INTO documents(embedding) VALUES ('{1,2,3}'),('{4,5,6}');
CREATE INDEX ON documents USING hnsw(embedding) WITH (dims=3, m=3, efconstruction=5, efsearch=5);Migration option 1: Use casting
To migrate to pgvector without altering the embeddings column type, and cast from real[] to vector:
-
Drop the
pg_embeddingextension:DROP EXTENSION embedding CASCADE;The
CASCADEclause removes the HNSW index that you defined withpg_embedding, which means that search queries fall back to using sequential scans until you installpgvectorand recreate your index. -
Create the
pgvectorextension:CREATE EXTENSION vector; -
Update your queries to cast embeddings data from
real[]tovector. For example, the following query casts embeddings data stored in theembeddingcolumn, defined as areal[], tovector.SELECT * FROM documents ORDER BY embedding::vector <-> '[3,1,2]' LIMIT 5; -
Recreate your index, casting the
real[]type column tovector, as shown:CREATE INDEX ON documents USING hnsw ((embedding::vector(3)) vector_cosine_ops);
Migration option 2: Use the vector type
To migrate to pgvector, changing your embeddings column type from real[] to vector:
-
Drop the
pg_embeddingextension:DROP EXTENSION embedding CASCADE;The
CASCADEclause removes the HNSW index that you defined withpg_embedding, which means that search queries fall back to using sequential scans until you installpgvectorand recreate your index. -
Create the
pgvectorextension:CREATE EXTENSION vector; -
Create a new table with the
vectortype:CREATE TABLE new_documents (id BIGSERIAL PRIMARY KEY, embedding vector(3)); -
Copy data over from your old table:
INSERT INTO new_documents (id, embedding) SELECT id, embedding::vector(3) FROM documents; -
Drop the old table:
DROP TABLE documents; -
Rename the new table to the name of the old table:
ALTER TABLE new_documents RENAME TO documents; -
Recreate your index. For example:
CREATE INDEX ON documents USING hnsw (embedding vector_l2_ops); -
Optionally, run a test query:
SELECT * FROM documents ORDER BY embedding <-> '[3,1,2]' LIMIT 5;
About pg_embedding
The pg_embedding extension enables the use of the Hierarchical Navigable Small World (HNSW) algorithm for vector similarity search in Postgres.
This extension is based on ivf-hnsw implementation of HNSW the code for the current state-of-the-art billion-scale nearest neighbor search system[1].
Neon also supports pgvector for vector similarity search. See The pgvector extension.
Using the pg_embedding extension
This section describes how to use the pg_embedding extension in Neon with simple examples demonstrating the required statements, syntax, and options.
Usage summary
The statements in this summary are described in further detail in the sections that follow.
CREATE EXTENSION embedding;
CREATE TABLE documents(id integer PRIMARY KEY, embedding real[]);
INSERT INTO documents(id, embedding) VALUES (1, '{0,1,2}'), (2, '{1,2,3}'), (3, '{1,1,1}');
SELECT id FROM documents ORDER BY embedding <-> ARRAY[3,3,3] LIMIT 1;Enable the extension
warning
The pg_embedding extension is no longer available for installation in Neon. Please refer to the notice at the top of the page.
To enable the pg_embedding extension, run the following CREATE EXTENSION statement in the Neon SQL Editor or from a client such as psql:
CREATE EXTENSION embedding;Create a table for your vector data
To store your vector data, create a table similar to the following:
CREATE TABLE documents(id INTEGER, embedding real[]);This statement generates a table named documents with a real[] type column for storing vector data. Your table and vector column names may differ.
Insert data
To insert vector data, use an INSERT statement similar to the following:
INSERT INTO documents(id, embedding) VALUES (1, '{0,1,2}'), (2, '{1,2,3}'), (3, '{1,1,1}');Similarity search
The pg_embedding extension supports Euclidean (L2), cosine, and Manhattan distance metrics.
Euclidean (L2) distance:
SELECT id FROM documents ORDER BY embedding <-> array[3,3,3] LIMIT 1;Cosine distance:
SELECT id FROM documents ORDER BY embedding <=> array[3,3,3] LIMIT 1;Manhattan distance:
SELECT id FROM documents ORDER BY embedding <~> array[3,3,3] LIMIT 1;where:
SELECT id FROM documentsselects theidfield from all records in thedocumentstable.ORDER BYsorts the selected records in ascending order based on the calculated distances. In other words, records with values closer to the[1.1, 2.2, 3.3]query vector according to the distance metric will be returned first.<->,<=>, and<~>operators define the distance metric, which calculates the distance between the query vector and each row of the dataset.LIMIT 1limits the result set to one record after sorting. You can adjust this value as required.
In summary, the query retrieves the ID of the record from the documents table whose value is closest to the [3,3,3] query vector according to the specified distance metric.
Create an HNSW index
To optimize search behavior, you can add an HNSW index. To create the HNSW index on your vector column, use a CREATE INDEX statement as shown in the following examples. The pg_embedding extension supports indexes for use with Euclidean, cosine, and Manhattan distance metrics. You must ensure that your search query syntax matches the index that you define. You will notice in the query examples below that each distance metric has a specific operator (<->, <=>, and <~>).
Euclidean (L2) distance index:
CREATE INDEX ON documents USING hnsw(embedding) WITH (dims=3, m=3, efconstruction=5, efsearch=5);
SET enable_seqscan = off;
SELECT id FROM documents ORDER BY embedding <-> array[3,3,3] LIMIT 1;Cosine distance index:
CREATE INDEX ON documents USING hnsw(embedding ann_cos_ops) WITH (dims=3, m=3, efconstruction=5, efsearch=5);
SET enable_seqscan = off;
SELECT id FROM documents ORDER BY embedding <=> array[3,3,3] LIMIT 1;Manhattan distance index:
CREATE INDEX ON documents USING hnsw(embedding ann_manhattan_ops) WITH (dims=3, m=3, efconstruction=5, efsearch=5);
SET enable_seqscan = off;
SELECT id FROM documents ORDER BY embedding <~> array[3,3,3] LIMIT 1;Tuning the HNSW algorithm
The following options allow you to tune the HNSW algorithm when creating an index:
dims: Defines the number of dimensions in your vector data. This is a required parameter.m: Defines the maximum number of links or "edges" created for each node during graph construction. A higher value increases accuracy (recall) but also increases the size of the index in memory and index construction time.efconstruction: Influences the trade-off between index quality and construction speed. A highefconstructionvalue creates a higher quality graph, enabling more accurate search results, but a higher value also means that index construction takes longer.efsearch: Influences the trade-off between query accuracy (recall) and speed. A higherefsearchvalue increases accuracy at the cost of speed. This value should be equal to or larger thank, which is the number of nearest neighbors you want your search to return (defined by theLIMITclause in yourSELECTquery).
In summary, to prioritize search speed over accuracy, use lower values for m and efsearch. Conversely, to prioritize accuracy over search speed, use a higher value for m and efsearch. A higher efconstruction value enables more accurate search results at the cost of index build time, which is also affected by the size of your dataset.
info
For an idea of how to configure index option values, consider the benchmark performed by Neon using the GIST-960 Euclidean dataset, which provides a training set of 1 million vectors of 960 dimensions. The benchmark was run with this series of index option values:
dims: 960m: 32, 64, and 128.efconstruction: 64, 128, and 256efsearch: 32, 64, 128, 256, and 512
For a million rows of data, we recommend an m setting between 48 and 64, and as mentioned above, efsearch should be equal to or larger than the number of nearest neighbors you want your search to return.
To learn more about the benchmark, see Introducing pg_embedding extension for vector search in Postgres and LangChain. Try experimenting with different settings to find the ones that work best for your particular application.
How HNSW search works
HNSW is a graph-based approach to indexing multi-dimensional data. It constructs a multi-layered graph, where each layer is a subset of the previous one. During a search, the algorithm navigates through the graph from the top layer to the bottom to quickly find the nearest neighbor. An HNSW graph is known for its superior performance in terms of speed and accuracy.
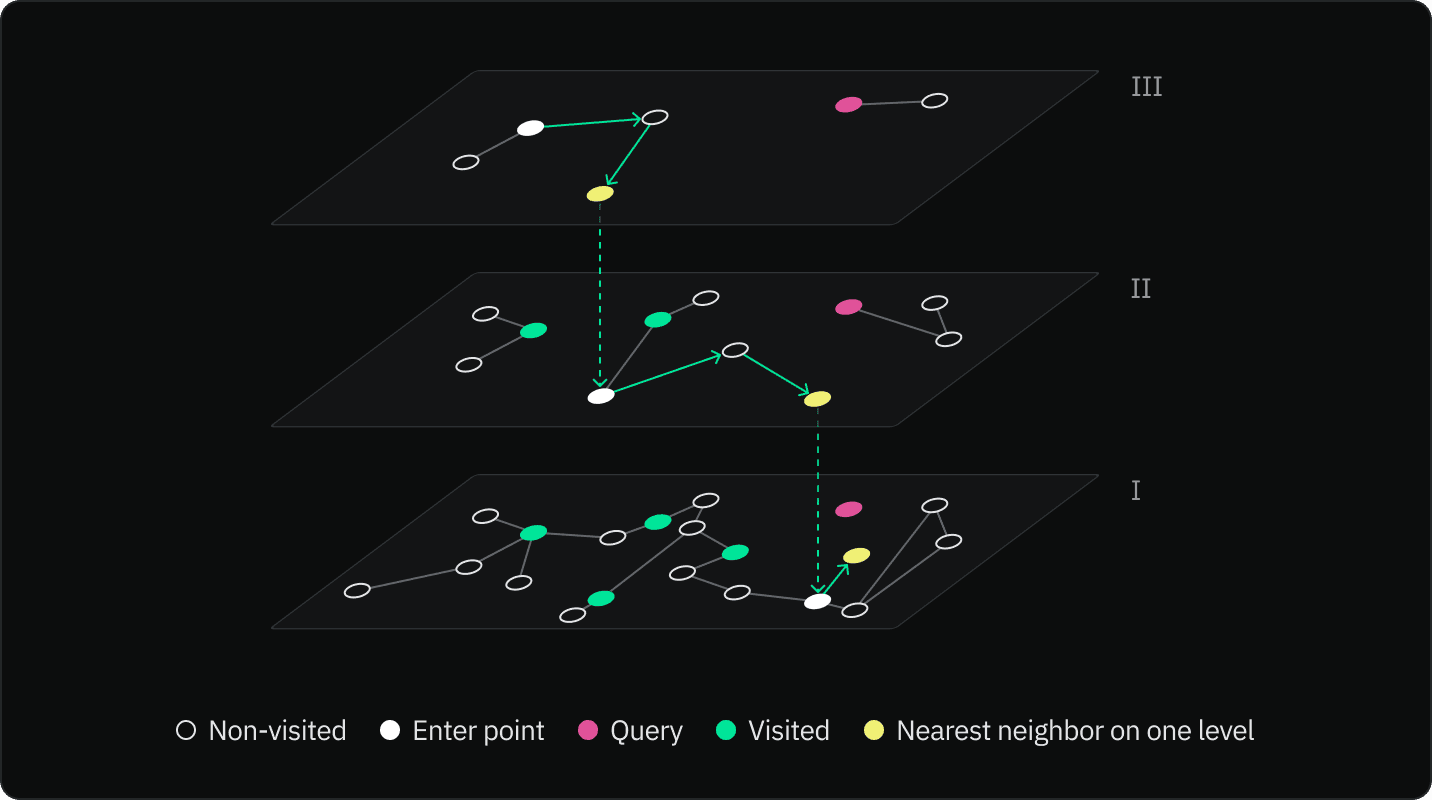
The search process begins at the topmost layer of the HNSW graph. From the starting node, the algorithm navigates to the nearest neighbor in the same layer. The algorithm repeats this step until it can no longer find neighbors more similar to the query vector.
Using the found node as an entry point, the algorithm moves down to the next layer in the graph and repeats the process of navigating to the nearest neighbor. The process of navigating to the nearest neighbor and moving down a layer is repeated until the algorithm reaches the bottom layer.
In the bottom layer, the algorithm continues navigating to the nearest neighbor until it cannot find any nodes that are more similar to the query vector. The current node is then returned as the most similar node to the query vector.
The key idea behind HNSW is that by starting the search at the top layer and moving down through each layer, the algorithm can quickly navigate to the area of the graph that contains the node that is most similar to the query vector. This makes the search process much faster than if it had to search through every node in the graph.
pg_embedding extension GitHub repository
The GitHub repository for the Neon pg_embedding extension can be found here.
Further reading
To further your understanding of HNSW, the following resources are recommended:
- Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs, Yu. A. Malkov, D. A. Yashunin
- Similarity Search, Part 4: Hierarchical Navigable Small World (HNSW)
- IVFPQ + HNSW for Billion-scale Similarity Search
Need help?
Join our Discord Server to ask questions or see what others are doing with Neon. Users on paid plans can open a support ticket from the console. For more detail, see Getting Support.
Last updated on